AIデータ抽出とは? AIがウェブスクレイピングを誰でも使えるものに変えた
2026年4月21日
ウェブページに欲しいデータがある — 商品リスト、価格表、連絡先ディレクトリ — それをスプレッドシートに入れたい。従来の方法はウェブスクレイピング:スクリプトを書き、CSSセレクターを調べ、ページ遷移を処理し、サイトのHTMLが来週変わらないことを祈る。AIデータ抽出は異なるアプローチです。人間が読むようにページを理解し、構造を自動的に識別し、整理されたデータを返してくれます — コーディングは不要です。
従来のウェブスクレイピング:強力だが壊れやすい
ウェブスクレイピングは数十年前から存在する技術です。基本的な考え方はシンプルで、プログラムがウェブページを読み込み、HTMLを解析し、div.price や table > tr > td:nth-child(2) のようなセレクターで特定の要素を抽出します。
これは以下の条件が揃えばうまく機能します:
- ページ構造が一貫していて、めったに変わらない
- スクリプトを書いてメンテナンスする技術力がある
- サイトのレイアウト変更時にデバッグする時間がある
しかし、ウェブページからデータが欲しいだけの多くの人にとって、従来のスクレイピングには現実的なハードルがあります:
- コーディングが必要。 HTML構造、CSSセレクター、XPathの理解が前提。
- セレクターが壊れやすい。 ウェブサイトのデザイン更新でセレクターが機能しなくなる。メンテナンスコストが継続的に発生。
- サイトごとに個別対応。 サイトによって構造が異なるため、それぞれ設定が必要。
- セットアップの手間。 ノーコードのスクレイピングツールでも、複数ステップの設定、ナビゲーションルールの定義、フィールドの手動マッピングが必要なことが多い。
データパイプラインを構築する開発者にとっては、この手間は合理的です。競合の価格情報を集めたいマーケターや公開ディレクトリのデータを収集したい研究者にとっては、ハードルが高すぎることが多いのです。
AIデータ抽出の仕組み
AIデータ抽出は根本的に異なるアプローチをとります。固定的なCSSセレクターに頼るのではなく、機械学習を使ってページの内容を理解します。
舞台裏で何が起きているか見てみましょう:
1. ノイズ除去
AIはまず、コンテンツではない要素を取り除きます:ナビゲーションメニュー、Cookieバナー、広告、サイドバー、フッターのリンク。残るのはページの実際のコンテンツです。
2. パターン検出
次に、AIが繰り返し構造をスキャンします — テーブルの行、商品グリッドのアイテム、ディレクトリのエントリ。「これはテーブルです」や「各商品カードのクラスは .product-item です」と教える必要はありません。コンテンツの構造自体からパターンを認識します。
3. フィールド識別
繰り返し要素ごとに、AIがフィールドを識別します:名前、価格、URL、日付、評価、説明文。これはHTML内の位置ではなく、コンテンツの意味的な理解に基づいています。
4. 構造化出力
結果は、ラベル付きカラムのクリーンなテーブルになります。CSV や JSON としてエクスポート可能で、後処理や手動のクリーンアップは不要です。
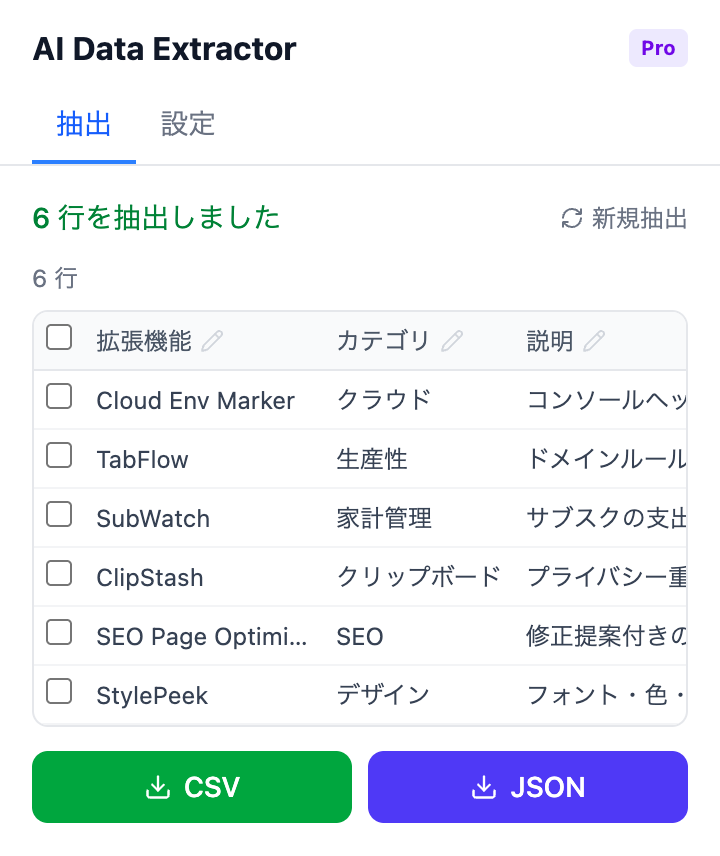
AIが抽出したデータが構造化テーブルに整理され、エクスポート準備完了
非エンジニアにとってなぜ重要か
セレクターベースのスクレイピングからAIベースの抽出への移行は、最大の障壁を取り除きます:ページのHTMLを理解する必要がないということです。欲しいデータがあるページを開くだけで、AIが構造を判断してくれます。
これにより、ウェブデータの抽出が以下の人々にとって実用的になります:
- マーケティング担当者 — 競合の価格情報や商品カタログの収集
- 採用担当者 — 求人サイトからの候補者プロフィール収集
- 営業チーム — ディレクトリからの見込み客リスト作成
- ジャーナリスト — 公開記録や政府データの収集
- 学生 — 学術プロジェクト用データセットの構築
これらすべてのケースで、ユーザーは欲しいデータはわかっているが、それを得るためにウェブ開発を学ぶ必要はないはずです。
ブラウザベースのAI抽出:最もシンプルなアプローチ
多くのAIデータ抽出ツールは、ダッシュボードやAPIキー、月額サブスクリプションを持つクラウドベースのサービスです。大規模なデータパイプラインを運用するチーム向けに作られています。
しかし、今見ているページからデータが欲しい個人ユーザーにとって、ブラウザ拡張が最も直接的な方法です。別のツールにURLを貼り付ける必要なし、APIの設定なし、外部サーバーにデータを送る必要もありません。
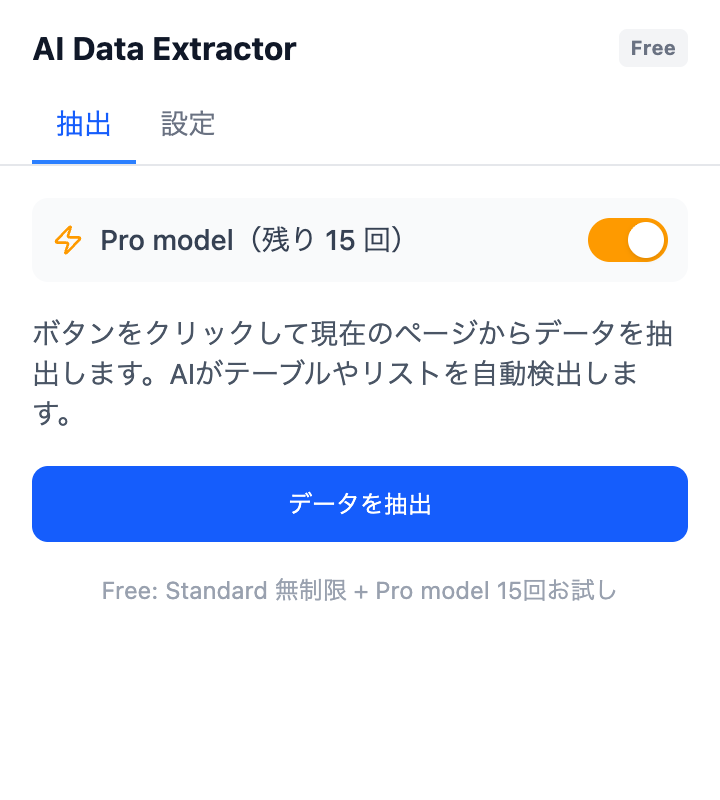
閲覧中のページからワンクリックで抽出
AI Data Extractor は、このAIパイプラインをブラウザ内で直接実行する Chrome 拡張です。任意のウェブページを開いて「抽出」をクリックすると、ページ上のテーブル、リスト、繰り返しパターンを検出します。エクスポート前にインラインで結果を編集することも可能です。
AIデータ抽出が向いているケース(と向いていないケース)
AIデータ抽出が最適なケース:
AIデータ抽出に向いているケース:
- 目に見える構造化データがあるページ(テーブル、グリッド、リスト、ディレクトリ)
- 1回きり、または時々のデータ収集
- カスタムスクレイパーを作る手間に見合わない多様なサイト
- プログラミング経験のないユーザー
あまり向いていないケース:
- 大量の自動パイプライン — 数千ページを定期的に処理する場合はクラウドスクレイピングサービスが適切
- 認証が必要なデータ — ログインセッションが必要な場合
- JavaScript で重く描画されるコンテンツ — 初期ページロードに表示されないデータ(ただし多くのツールは対応済み)
- ピクセル単位の精度が必要な場合 — 手動調整したセレクターのほうが信頼性が高い
日常的なデータ収集 — 結果テーブルの取得、商品リストの作成、ディレクトリエントリの抽出 — にはAI抽出がどの代替手段よりも速くて簡単です。
まとめ
AIデータ抽出は、ウェブスクレイピングを改善しただけではありません。そもそもスクレイパーを書くつもりのなかった人々にとって、ウェブデータをアクセス可能にしました。ウェブページにデータが見えるなら、それを使えるべきです — それがAI抽出が実現することです。
試してみませんか: AI Data Extractor はウェブページをワンクリックで構造化 CSV/JSON に変換します。無料で利用可能 — アカウント不要。
役に立ちましたか? Chrome Web Store でレビューしていただけると、他のユーザーがツールを見つける助けになります。
ご質問やフィードバックは support@joifup.com まで。